rand(life)
무작위로 영어->한국어, 한국어->영어 단어시험지 추출 본문

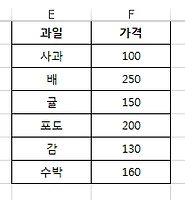
이렇게 단어시험 문제를 낸다고 합시다.
시험범위는 B1~D1이고
총 시험문항수는 D4
우리말 뜻쓰기 유형 문항수는 C3
영어철자쓰기 유형 문항수는 C4
무작위로 저 조건에 맞게 단어를 추출하려면 어떻게 해야할까요?
대개 이런 유형의 문제들은 배열함수가 답입니다.

편의상 4번 문항의 수식을 예로 들겠습니다.
B13에 들어가는 수식은 위와 같습니다. 배열수식이므로 마지막에 Ctrl-Shift-Enter입니다
수식의 각 부분의 해석은 다음과 같습니다.
수식 | 해석 | 기능(함수) |
=IF($A13<=$D$4, | 문항번호가 총문항수보다 적거나 같으면 이후 수식 진행, 아니면 공백출력 |
|
OFFSET |
| 위치 이동 함수 |
(IF($A13<=$C$3,LIST!$C$1,LIST!$D$1), | 미리 정해진 영어->한국어 문항수보다 문항번호가 작을 때, list시트의 C열(영어) 첫행 선택. 아니면 D열(한국어) 첫행 선택 | offset함수의 인수. 이 위치에서 특정 거리만큼 이동함. |
MOD | 나머지의 크기에 따라 문항번호에 해당하는 순서의 단어의 위치를 구함 | 나머지 구하기 |
(SMALL | 조건에 맞는 단어들 중 몇 번째로 작은 수에 해당하는 순위를 가진 단어를 찾음 | 배열함수에서 크기순으로 나열하기 위해 자주 쓰는 함수. 배열 중 몇 번째로 작은 수를 찾는다. |
(IF(IFERROR | 시험범위에 해당하는 단어 배열만듬 | 배열이 시작됨 |
((SUBSTITUTE(LIST!$A$2:$A$99,"day","")*1>=$B$1)* | 단어 목록 중 시험범위에 해당하는 단어들의 번호만 배열로 출력함. day1->1, day2-> 2.... B1은 시험범위 시작일 | 배열1 |
(SUBSTITUTE(LIST!$A$2:$A$99,"day","")*1<=$D$1) | D1은 시험범위 마지막일. 두 개의 substitute 함수는 논리곱*으로 연결되어있어, 둘 다 TRUE이여야만 값이 출력되고 그렇지 않으면 FALSE로 0으로 취급 | 배열2 |
,0), | 오류값이 있으면(즉 시험범위가 되는 날짜에 해당하지 않는 단어이면) 0을 출력 | iferror함수의 인수 |
LIST!$G$2:$G$99*10^5+ROW($G$2:$G$99)), | list시트에서 단어마다 rand()함수로 동순위 없는 순위를 매겨둠.(G2:G99) 시험범위에 해당하는 단어들의 번호에 대해서는 그 순위에 10,000을 곱하고(단어수가 2~99보다 더 많아지면 간섭을 받을 수 있으므로) 2~99까지의 숫자와 더해줌. 2~99의 숫자는 list시트 상에서 해당 단어의 위치를 나타내므로, 실질적으로는 단어를 골라내는 역할을 함 | IF구문의 결과값 |
$A13) | 위의 계산 결과로 나온 단어의 순위*10,000+(2~99)한 배열 중에서 작은 순서대로 문항번호만큼인 숫자(예를 들어, 문항번호가 4번이라면 4번째로 작은수)를 고른다. 실질적으로는 rand()함수로 정해둔 단어의 순위상으로 4번째에 해당하는 수를 고른다. | SMALL 함수의 인수. |
,10^5) | 위의 결과값을 10,000으로 나눈 나머지를 구한다. 즉, 위에서 더해주었던 2~99의 숫자와 같다. 즉, list시트 상에서 해당 단어의 위치를 알려준다. | MOD함수의 인수. |
-1,) | 머리말, 항목의 제목 때문에 이동할 위치를 수정한다. | Offset함수의 인수. |
,"") | 문항번호가 총문항수보다 크면 공백출력 | IF함수의 인수. |

설명 중간에 나오는 rand()함수로 순위를 매긴 것은 위와 같은 모습입니다. F열에는 =rand() 함수를 입력하였고, F열의 값으로 순위를 매긴 것이 G열입니다. rand()함수는 0에서 1사이의 숫자를 만들어내는데, 최대 소수점 17자리까지의 숫자를 무작위로 만들어내므로, 무작위로 번호를 부여할 때 많이 쓰는 방법입니다.
첨부화일도 있으니 각자 연구해보시길.
출처: 네이버지식인